| ADVERTISEMENT |
| crossMarket Premium: Boost Your Productivity The online network for all Across users brings together translation service providers and buyers. Become a premium member and benefit from unlimited possibilities to find and contact potential customers. For prices and a list of all premium features, visit www.crossmarket.net. |
|
1. The Future Awaits? (Premium Edition)
|
Here is a slide from a presentation I gave a couple of weeks ago about how the use of the main data assets used in the translation process is in an ongoing process of change:
(Admire my beautiful PowerPoint slide design? Ralph Waldo Emerson, that never-ending source of smart-sounding quotes, had something to say about this: "Nothing is more simple than greatness; indeed, to be simple is to be great." J)
At any rate, the point of the slide was this: The way we deal with our data resources has already changed significantly and will continue to change. Everything that's in black is the "traditional" way of dealing with each respective resource, and the grayed-out parts are those that are in the process of being introduced (the darker they are, the more they are already being used). For instance, most translation environment tools today automatically use subsegments from the translation memories. This has fundamentally changed the way we deal with TM data (and has made some of our preconceived notions about TMs largely obsolete, such as the "big momma" TM that holds everything or the idea that TMs don't need to be maintained carefully). Recently I've been frequently discussing the more productive ways of using MT away from the post-editing scenario, and it's nice to see that others agree. For instance, take a look at what Common Sense Advisory's Arle Lommel says about this (especially his last bullet point). Still, a lot more could be done in this area by some of the translation environment tools (you'll notice that the gray for this item is a little lighter). Much can still be done with terminology databases and glossaries as well, especially how they interact with results from the translation memories and machine translation. Tools such as Déjà Vu are leading in this particular aspect, but even they could do a lot more. (You'll notice the very light gray.) The last point might be impossible to read because the gray is so light, but here's what it says: Automatic integration of other, external resources (glossaries, dictionaries, corpora like Linguee...) Now that we've started to look at translation memories and machine translation as resources for small segments and single words, it just doesn't make sense that our tools don't give us automated access to external resources in the form of corpora. Naturally these would include corpora such as Linguee, the TAUS Data Cloud, and many others (such as the Canadian Hansard corpus, the many different corpora at OPUS, the many EU resources, and on and on). Admittedly, integrating some of those corpora would require a lot of work, but tools like the one from TAUS have already done much of the work for us by categorizing their data and using text mining. And to some degree, Linguee has done that also -- at least as far as the text mining (the automatic recognition of term pairs). Or why is it that specialized dictionaries have to be imported or run alongside my translation environment tool when it would certainly be possible to run automated queries to the dictionaries I assign to a project, show the translated terms automatically in the TEnT's interface, and/or automatically integrate into my translation? Across and SmartCat are two tools that have dipped their toes in these waters by providing possible access to some specialized dictionaries, but the lookup in those is still unnecessarily manual. memoQ has been a pioneer in giving automatic access to the EuroTermBank termbase -- and while I think that most users actually didn't find that particularly helpful because of too much noise data (it's not possible to access terms by category), the idea was still good. The dictionary lookup tool Wordfinder has been looking into ways to bring data from their many dictionaries directly into the translation environment, but they haven't made too much progress on that I'm afraid. ("I triple-double-dare you, Ole!") I have sometimes been chided by technology developers for being too naïve in making propositions that are much harder to implement than I make them sound. My feeling is that this will happen here as well. And they're probably right. Even I can see some real challenges in this, and I don't want to triple-double-dare poor Ole from Wordfinder alone; instead, it's a dare for all of the translation technology community. It would be fantastic if we could have intelligent and highly automated access to already compiled resources that are not necessarily residing on our computer. One thing we need to keep in mind is the story of Linguee. The makers of Linguee were very hopeful that the translation community would be interested in partnerships to finance the development of more intelligent tools than the ones Linguee uses right now, tools that look at the complete sentence when searching for just one term from within the sentence and giving us ("us" as in professional translators who were willing to pay 5 euro a month) context-sensitive access. The tool was phenomenal -- phenomenal as far as its functionality, but unfortunately not as far as our buy-in. We were too cheap. So Linguee buried the tool. Let's hope that we've learned and this won't happen again if we ever see a tool like I imagine. |
| ADVERTISEMENT |
Fresh on the Memsource blog:
|
|
2. Studious Developments
|
| I can't even remember when I last wrote a product review of SDL Trados Studio. (I just checked in the archives -- it's been about a year.) To remedy that fact, I asked Daniel Brockmann and Massi Ghislandi to meet with me and update me on two projects that I knew had been in the pipeline for some time: an online editor and SDL's self-learning machine translation, which will be termed "Adaptive MT." Turns out that my timing was accidentally impeccable. The SDL Translation Online Editor was released just last week and SDL has committed itself to rolling out Adaptive MT later this year still (right now it's in a relatively shaky alpha version). Let's talk about the online editor. At this point, it's probably not exactly what you would expect. It's neither a quasi-clone of the SDL Trados Studio desktop environment nor is it actually meant (at this point) to play a role within the Studio workflow. Instead, the online editor (which runs on Chrome, Edge, and Firefox -- IE is not supported) is really meant for a different target group: people with an occasional need for translation, who really are not well-versed in things like "translation memory," "termbases," or -- shriek -- "quality assurance." This is reflected in both its interface and functionality. There is a translation memory, but only one that contains previous translations that were committed in the online editor interface (no way to import external data). There is no termbase, and the controls that match the available features are very limited as you can see in the screenshot below.
You can also see that, by default and if there are no TM matches, there is machine translation (by SDL Language Cloud), and you can see that at this point there are some problems with unnecessary tags (which I assume is due to the early release version). Also, the only file types that are supported are Office formats and text files. Good enough for the occasional translator, not so much for us. So what's the deal with this? Well, SDL wants to make its foray into the world of cloud-based interfaces slowly and carefully. As you can imagine, there eventually will be more functional and professionally usable (by that I mean "professional" as in "translation professional") online editors, but the powers-to-be at SDL might be wise not to hasten it only to see it crash and burn. I thought it was very positive when Daniel Brockmann insisted that a fully functional future online editor will not be a clone of the desktop product, but will be geared toward a potentially different set of expectations that users have from a cloud-based product (such as greater simplicity). That would be very wise indeed. (See the rest of this article in "Part 2" below.) |
| ADVERTISEMENT |
| MateCat. More matches than any other CAT.
Translate in the cloud, faster than with any other CAT tool.
Supporting over 60 file formats and now also Google Drive files.
|
|
2. Studious Developments (Part 2)
|
| On to Adaptive MT. It's relatively easy to train rules-based machine translation (like PROMT, SYSTRAN, and Lucy MT) on the fly -- even if the process of entering new terms and phrases tends to be rather cumbersome. (You have to go through a number of options to teach the system not only the new word or phrase but also information about it such as part of speech or other grammatical information). But the good thing about an RbMT system is that it is possible to finagle the outcome -- which traditionally has not been the case with statistical machine translation systems. Here the data that the system uses to create translated text sits in so-called "phrase tables" that typically cannot be written to interactively. So rather than learning interactively as you make changes to MT suggestions, you (or a system administrator) will have to set the system up to rebuild the MT engine with updated data on a regular basis. This is a very cumbersome and time-consuming task, not to mention that it's super-frustrating to have to wait a few days or even more before you can stop changing the same poor output again and again. There are some exceptions to this. One was developed as part of the EU-funded MateCat project. They developed a process that uses a technique called "cache-based online adaptation for machine translation." (You can read about it right here.) Very unfortunately, this technology did not make it into the commercialized version of MateCat, but it looks like the technology's current "guardian" -- the Fondazione Bruno Kessler -- has ported this technology to yet another EU initiative, the ModernMT project, which "will overcome four technology barriers that still hinder the wide adoption of currently available MT software by end-users and language service providers." We'll see what will come out of that. I certainly hope that in this case, the technology will end up seeing the public light of day. Another tool that has tackled this is Lilt, and I just recently wrote and recorded a video trying to explain just how it manages to do this. (You can watch the video right here.) And later this year, SDL Trados Studio (as well as other SDL translation products) will be equipped with a feature that, while using a statistical machine translation engine, (almost) immediately learns from your corrections. All you have to do to make that happen is to, well, make said corrections. Here's how it works behind the scenes: Rather than training a machine translation engine with translation memory data you might have collected, you select the base-line engine (the non-specialized engine) of the SDL Language Cloud MT offering and then customize that. Ah, you might say, my work will benefit everyone else as well! No, not quite (in fact, not at all). That's because while you do share the core MT engine with others, the customizations that you enter will not be seen and/or used by others. How is that possible? Well, just as in most statistical machine translation products, the actual phrase table (see above) stays unchanged by your corrections, but whatever corrections you do make are stored in your "private phrase table" within Language Cloud. That private collection of changes essentially modifies the output of the engine to make it produce results that are more similar to your previous corrections. The demo that Daniel and Massi showed me was really rather impressive. One term within a lengthy sentence was altered, and after a short delay (thus the "almost" immediate learning mentioned above) that term became the preferred term for the next lengthy sentence, despite the fact that it really was not a commonly used term. The tool allows you to create as many "instances" of a customized engine as you want (which might well be necessary for different clients), and while it will be available at first only between English and French, Italian, German, Spanish, and Dutch, you should be able to expect other language combinations to follow suit quickly. I'm happy to see this feature and look forward to seeing how it will perform with a large number of changes and what the actual improvements will be (in an internal test that SDL did last year, they said they had to perform an average of 250 fewer edits in a post-editing scenario of 300 segments in an EN>FR project). I'm also interested in how this feature will be beneficial in a non-post-editing scenario with the machine translation as just one additional resource accessed by features like AutoSuggest (early feedback from SDL is that the implemented changes will indeed change there also). |
| ADVERTISEMENT |
| We Have ALMOST Nothing To Say This Month. Except... Stay Friendly! Join the trend! Download the most comprehensive CAT system ever! Use it. Love it. Work it. |
| 3. Free Is Fair (Premium Edition) |
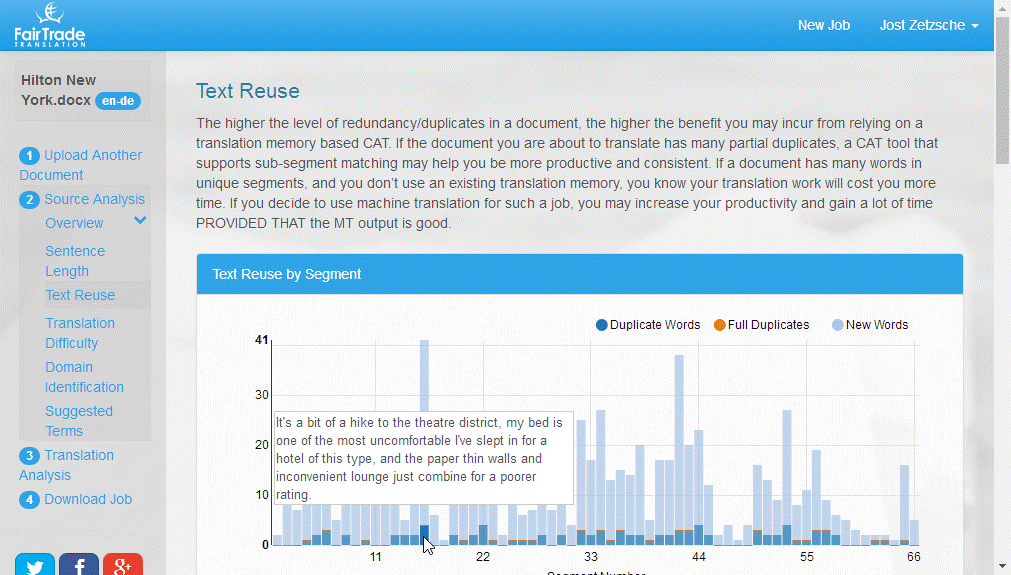
| Last November, I reported on Fair Trade Translation, a service provided by two veterans in the translation industry, Gert van Assche and Daniel Marcu. Fair Trade Translation allows you to upload MS Office files, text files, or (SDL)XLIFF files. These will then be analyzed and machine translated (by Google Translate, Microsoft Translator, or SDL Language Cloud, whichever provides the "best match"). The translations will be categorized into "bad" and acceptable, and you will be given an estimate of the quality of the machine translation so you know how profitable it will be to work on that file or project. You can read the more in-depth description in the article that I linked to above. There are a couple of things that have changed since I wrote the first article, though. Most important is the price, which is now completely free. It looks like Gert and Daniel still have some bugs to iron out in how they communicate that, but as of now (and for the near and mid-term future), this service is free. Also, the interface has changed significantly. It has become both more simple and more complex. It's very simple when you first arrive. All it says is: "Professional Translators: Are you getting the most from your work? Analyse and Optimize your translation job with Fair Trade Translation." And then there is a chance to upload a file. I'm a little underwhelmed by this. While it's charming to have British and US spelling mixed in this, it seems that we need a little more information for this new kind of service. Yes, Daniel and Gert have done a good job trying to explain their service on LinkedIn and other platforms, but my sense is that the typical translator needs to know a little bit more to understand what this is about. (Including, by the way, some privacy-related information with the data being sent to Google and Microsoft and all.) So, I imagine that there will be more informative incarnations of the starting page. Once you get beyond the first page, it becomes much more informative. The analysis page provides a lot of interesting and graphics-based info as in the following screenshot:
I don't necessarily always agree with the conclusions or methods of analysis, though. Take this one for instance: "A sentence length analysis is the simplest way to look at a source document and estimate how difficult it is to translate. A document with many short sentences is likely to take less to translate than a document with long, rambling sentences." Yes, "rambling" can be difficult, but "short" does not necessarily make for an easier translation. Still, you can find some helpful pointers in the tool to see how difficult a new text might be -- especially if you are not intimately familiar with the subject matter. And the machine translation? Typically as poor as one would expect, but the system was quite accurate in its assessment of which of the machine-translated segments were useful and which not (12 out of 66 segments in my sample file). When I asked about the lack of transparency of privacy issues with the data, Daniel said the following: "Individual translators did not express concerns about the confidentiality of data. You are right though: that is going to be important in the context of larger LSPs. We plan to make it explicit on a FAQ page once we begin focusing on that segment as well." Again, I'm not sure that this is something I would necessarily agree with. I would argue that most translators are quite concerned about data confidentiality, but if that's the feedback he gets from his user group, then that's what it is. Last time I talked about Fair Trade Translation, I closed like this: "I'm not sure whether this system is going to completely change how most of us work -- it might mean some changes for some -- but what I really, really like about it is this: It's just so creative and it shows that we are doing very well if we have smart folks coming up with such smart solutions for us." I couldn't have said this any better. |
| ADVERTISEMENT |
| Research by SDL shows that when it comes to translation jobs, quality is 2.5x more important than speed and 6x more important than cost. It also revealed that a high amount of translation professionals are not aware of any metrics or models used for assessing translation quality. Discover the challenges translation professionals face in delivering high quality translations and the expectation of how technology can help in the future. Read the free eBook on quality, SDL's second installment from the Translation Technology Insights Research 2016. |
5. New Password for the Tool Box Archive
|
| As a subscriber to the Premium version of this journal you have access to an archive of Premium journals going back to 2007. You can access the archive right here. This month the user name is toolbox and the password is Vociferous. New user names and passwords will be announced in future journals. |
| The Last Word on the Tool Box Journal |
| If you would like to promote this journal by placing a link on your website, I will in turn mention your website in a future edition of the Tool Box Journal. Just paste the code you find here into the HTML code of your webpage, and the little icon that is displayed on that page with a link to my website will be displayed. If you are subscribed to this journal with more than one email address, it would be great if you could unsubscribe redundant addresses through the links Constant Contact offers below. Should you be interested in reprinting one of the articles in this journal for promotional purposes, please contact me for information about pricing. © 2016 International Writers' Group |
|