| ADVERTISEMENT |
| Focus on Translation, not Administration. Celebrate Translation Day with Us! www.translation3000.com/for_toolkit_readers Valid until September 30, 2017. With Best Greetings, Your Team at Advanced International Translations. |
|
1. DeepL
|
| You might have asked yourself: Shouldn't this Tool Box Journal have been in my inbox about a week ago? And, yes, that would an adequate question to which there is a very deepL answer. I have been waiting for almost two weeks to talk to someone at DeepL/Linguee about, well DeepL (which, by the way, is pronounced deep-l). They've been a little overwhelmed by the immediate attention they received when, with great fanfare, they released their neural machine translation engine between English, German, French, Spanish, Italian, Polish, and Dutch. This new engine is producing results that in many cases seem to be better -- and sometimes significantly better -- than both Google Translate and Microsoft Bing Translator. So, I was finally able to talk with Jaroslaw Kutylowski, DeepL's CTO, today, which allowed me to complete this Tool Box Journal. There was a lot Jaroslaw could legally and strategically not say, but what he could say was still very interesting. For instance: When I asked him how long they've been planning to have a machine translation engine, he told me that it really only started to occur to them about a year ago, when neural machine translation first popped up and became everyone's favorite topic to talk about. It does make sense, though, that the company known for Linguee (the whole company is actually called DeepL now with Linguee being one of its products) is using its somewhat curated corpus in the EU languages plus Russian, Chinese, and Japanese to train a neural machine translation engine. How much the curation/editing/dictionary building plays a role in the relatively high quality according to the company's own estimation was among the questions for which I received no answer. While there was no time commitment to the immediate roadmap, there is particularly much emphasis on adding new languages, which likely will be the ones that are already covered by Linguee but could include others as well. What also is on the roadmap is the development of an API (there is an unofficial and unwelcome one right here, but you would be not well-advised to integrate that since that will be blocked soon by DeepL). The API, or application programming interface, is particularly important if DeepL is to be used by professional translators who would want to use it not on a webpage but integrated into a translation environment tool. And at that point of the discussion I knelt down (actually I didn't, but I would have if that would have made a difference) and asked that in exchange for payment for this use of such API, DeepL would commit itself to not using the data that is being translated for training purposes (which it does right now) -- along the lines of what Google Translate does. And while Jaroslaw did not completely commit himself, he said there would be a very great likelihood that this indeed would happen. This is really, really good news because this is what makes this essentially usable for translators. Microsoft has unfortunately never embraced that idea, using the data you upload through its API for training purposes (which some of your clients might not mind, but many others will, no matter how much Microsoft assures us that it will only happen in a high level and temporary manner). Google has understood why it should not do that, and now seemingly DeepL has as well. I also asked whether there were champagne corks popping at DeepL's headquarters in Cologne when just a few days after DeepL was launched Google announced new developments for their machine translation system. It seemed to me the timing was just too close to be coincidental -- but who knows. (DeepL doesn't know either, so the champagne question also went unanswered, but I'm pretty sure if this had been a video call, there would have been a knowing smile on Jaroslaw's face.) One thing I had been very surprised about was the "voice" of the announcement -- which was decidedly un-German and very American in the sense that it was rather uncompromising (the actual term that came to my mind was "hyperbolic"). Well, Jaroslaw said, you have to be self-confident when you have good reason for it, even if it might not match the prevailing culture of where you are. And I guess that's a pretty healthy way of looking at things. And to come back to the quality, you can see some numbers in the press release that show impressive quality gains, which partly matched my own -- very subjective and limited -- testing. Particularly when it came to advanced technical and semi-technical texts, the quality of the English> German direction was decidedly better and more natural than Google's and Microsoft's neural output. When it came to relatively high-brow press material, however, the pendulum seemed to swing the other way. But again, the sample I had was obviously very small. Here is something I found interesting and reassuring. When we first looked at the neural outputs that Microsoft and Google have been producing in comparison to their earlier statistical engines, they seemed oh-so elegant and fluid. Suddenly, though, when compared to this, they looked terrible again. This reminded me how easily impressed we are with advancements but then often forget to look at the results in their own right to realize that they all have a very, very long way to go, including DeepL. Here is one interesting little experiment some of you have probably also already tried: If you retrieve data from Linguee to have it translated by DeepL, you do not get the existing translation that already can be found in Linguee and that DeepL was trained on but a completely new one, all done with the neural computer "brain." Chances are this would have been different if they had built a statistical machine translation program where the original fragments might in fact have been reassembled -- but that's just not how neural MT works (see also the article about Google's statistical MT in this Tool Box Journal). |
|
ADVERTISEMENT
|
| Call for Proposals for think! Interpreting 2018 think! Interpreting 5 will take place in Boston, USA on March 13-16, 2018, as part of GALA's 10th Anniversary Conference. The Call for Proposals is now open through 22 September, 2018. Submit your interpreting-related proposal today! |
|
2. PK! (Premium Edition)
|
| Arguably the most important utility you need to be able to receive and send files properly is a compression program. Nothing can frustrate a client or customer more than receiving a file of several megabytes that would have been maybe a tenth of the size or even less if it had been sent in compressed format, or receiving one file instead of many (including a correctly maintained folder structure). There are dozens of different programs out there, including PKZIP from the "inventor" of the zip format (more on that below), ZipGenius or the powerful 7-Zip, or -- if you exchange a lot of files with other users who use Macs -- you might want to look into using Stuffit, which not only unzips Windows-specific but also Mac-specific compression formats, including SIT and SEA. Windows also contains its own zip program, but its feature set is very limited, and Mac computers come with one that frustratingly cannot deal with password-protected files. So you do want to have an extra program to deal with compressed files. Some file formats, such as RTF or BMP, are particularly well suited for compression because they can be minimized significantly; others, such as JPG, GIF or PDF, often shrink very little when being compressed because they are compressed in themselves to start with. 7-Zip, my long-time personal choice, works with a large number of compressed file formats and has other advanced features that I like (oh, and it's free). As with most other programs of its kind, it is closely integrated with Windows/File Explorer, i.e., a right-click on any file, group of files, or folder(s) gives you access to the program. Like anything else, it's not perfect -- it looks very '90-ish and tends to push its own compression standard a little too much -- but it has some really helpful features that will be appreciated by many. While in earlier versions of compression utilities, the context menu tended to be rather cluttered with a number of options, newer versions typically put an end to this mess by giving only one option. This provides access to a whole new submenu with the various old and new zipping options (which, by the way, are configurable), including in some cases the ability to directly email the newly created zip file (which saves space on your hard drive and means one less step in your workflow). For the above-mentioned password protection ability, select the Create archive with options command (or however your program names it), which will open a dialog that gives you access to the password option. Another feature that most zip tools offer through the options menu is the ability to split files into smaller chunks so that they fit into an email or on a storage device. Once you want to use the file(s), the tools allow you to reassemble them into one large zip file again. And here's another little time-saver. Often I receive five different zip files for a project. It has always annoyed me to have to right-click on each of them individually and select the appropriate unzip command so the files will be unzipped into a folder that carries the name of the zip file. Then I discovered that you can also select several zip files at a time (by holding the CTRL key and clicking on each of them). You can then select a command to extract them, "Extract to "*\"," which creates as many folders as there are zip files. And finally, here's my favorite topic when it comes to compressed files: Many, many file types that seem to be highly specialized formats are indeed zip files. Take Office files (both Microsoft and OpenOffice/LibreOffice) or most of the package files that are being used and generated by translation environment tools. Here is how you can find out. Open the file with a text editor (Notepad will do) --BUT DON'T SAVE IT! (Scared by the all caps? You should be, because once you save it you break it -- unless it's a text-based file.) If the first two letters in that otherwise likely illegible file are "PK" it's a zip file. Just as easy as that. Why PK? There is a very profound reason for that. The developer of the format's name was Phil Katz. (Having his initials memorialized in billions and billions of files didn't help poor Phil, who died in 2000 of alcoholism...). So what does this mean for you? A: You can actually work with that file to some degree no matter whether you have the originating program or not, and B: You just demonstrated that you're a geek. One way to work with the non-zip-extension zip file is by using your zipping program to unzip it to inspect and possibly edit the contents -- that might be really helpful if you have received a package file from translation environment tool A and would like to use tool B for that without having a clear way to do so. Or -- if you know what you're doing -- you can also delete certain parts of the zip file to make it smaller or more easily digestible (one client of mine always sends a very outdated termbase along with every project package file that I routinely delete before importing the project). |
| ADVERTISEMENT |
|
The My SDL Trados app, at your finger tips
My SDL Trados is a new, free companion app that allows you to stay in touch with the latest SDL Trados news, education and professional development resources on your mobile phone or tablet.
|
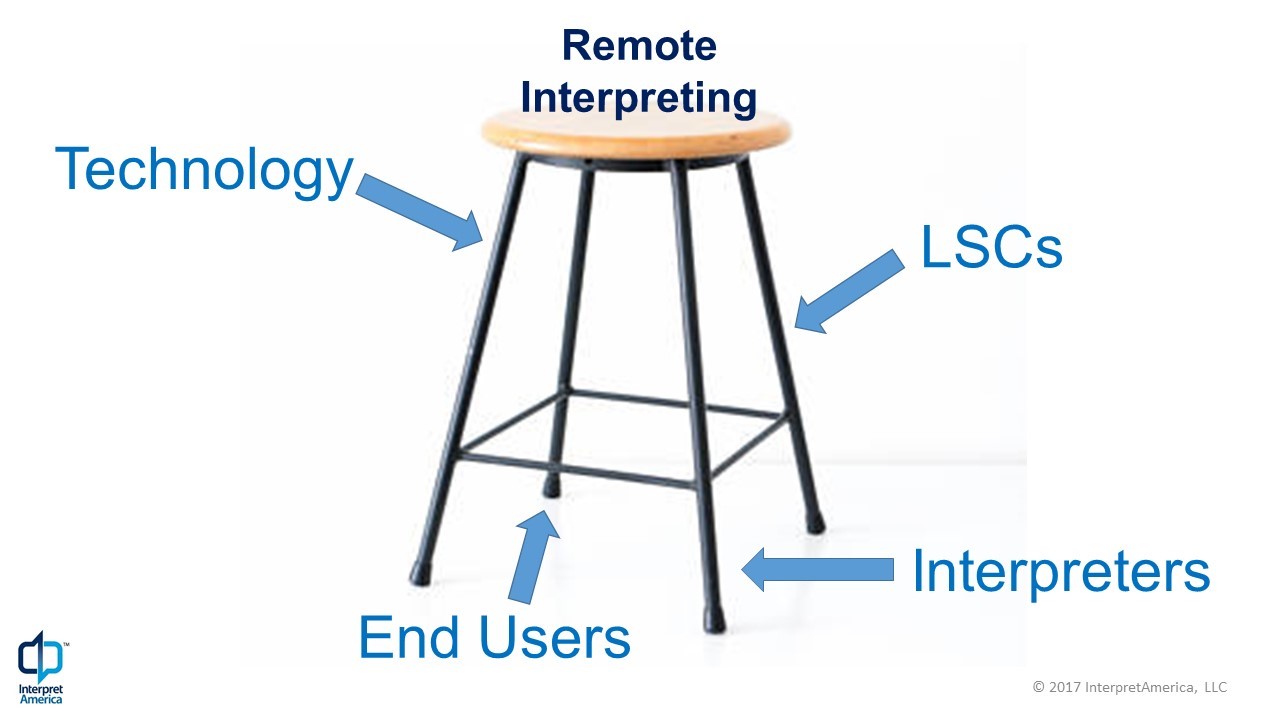
3. The Tech-Savvy Interpreter: The Four-Legged Stool of Remote Interpreting (Column by Barry Slaughter Olsen)
|
| It's difficult to identify a tipping point before the tip occurs. I don't claim to have a crystal ball or clairvoyance, but 2017 sure feels like a tipping point for remote interpreting from where I stand. I've been following this market closely since 2011 when InterpretAmerica identified remote interpreting as a force that had huge potential to both expand and disrupt the interpreting profession. Let me explain what I see. To do so, I'll make use of a familiar analogy -- the four-legged stool. When the stool has all four legs, it is firm, solid, and works well. But remove one or more of the legs, and it becomes unstable, tips over easily, and really isn't good for much.
Like the legs of the stool, four elements must be firmly in place for remote interpreting to be sturdy, dependable, and work well. They are: the end users, the technology, the interpreters, and language service companies (LSCs). End Users No service provider can exist without customers, and at its core, interpreting is a service. That remains true no matter where or how the service is provided, for whom, or by whom. Without this leg, the other three have no reason to exist, which is why I list this leg first. Customers, i.e., end users, have been asking -- many clamoring -- for new remote interpreting delivery models for years. In some cases, they want remote interpreting because of shrinking budgets and growing mandates. In others, the current face-to-face interpreting delivery models simply don't provide the service fast or conveniently enough. Finally, end users are asking for interpreting services for virtual meetings that take place online. Traditional delivery models simply are not set up to provide interpreting in these circumstances. What all this means is that the demand is there for both remote consecutive and simultaneous interpreting. End users both need it and want it. The Technology For decades, the technology leg of the remote interpreting stool was either totally absent, unstable, or prohibitively expensive. It was easy to dismiss the idea because we could simply say "the technology just isn't there yet." That is clearly no longer the case. The technology is here and it works. The cost has also come down dramatically. These facts are now forcing interpreters in all settings and specializations to take a long, hard look at how we work and why. The number of technology offerings for remote interpreting delivery has increased quickly in the last two or three years. This has happened because foundational telecommunications technologies are making high-quality audio and video transmission over the Internet available to anyone with a broadband internet connection and a video and audio enabled endpoint (from a telepresence studio to a smartphone and everything in between). It is as though we now have a blank digital canvas that innovators are designing and creating on with few things constraining what is possible. In the early stages of this digital wave, it was the outsiders who were trying to disrupt the interpreting space. As the technologies have gotten better and the use cases more specific, remote interpreting startups have sharpened their focus and are gaining traction. But perhaps the most telling development in this area in recent months is the announcement by leading simultaneous interpreting equipment providers that they have launched or are close to launching their own remote interpreting platforms. (See KUDO, launched by MediaVision CEO Fardad Zabetian and the announcement made by Congress Rental Network President Gilles Goudreault earlier this year.) When the incumbents tip their hand, it's a safe bet that the tipping point has arrived or is fast approaching. The Interpreters The third -- and most important -- leg of the remote interpreting stool is the interpreters. Remote interpreting has received a cool to outright hostile reception among many practicing interpreters whether in clinics, courtrooms or conference centers. And with good reason in some cases. The pressure on interpreters comes from several quarters. Interpreting remotely, audio only or with video, requires additional skills and cognitive tasks that take training and practice to obtain. Typically, employers and end users are ignorant of the stress this puts on interpreters, who have to play catchup at a time when very little training is available. In healthcare interpreting, we are seeing a trend in some hospitals to replace their entire on-site interpreting staff with remote interpreting. Either on-site interpreters are asked to sit in a room in front of a video screen all day or they are summarily fired and a remote interpreting service is brought in. The lack of best practices and guidelines for employers and end users has a real, negative impact on interpreter working conditions in these circumstances. Finally, remote interpreting requires interpreters to make a sometimes-significant investment in equipment to set up a remote workspace that meets the often-stringent privacy requirements of clients. In years past, I had observed a generally dismissive attitude regarding remote interpreting. With its increasing penetration into the market, however, that attitude is beginning to evolve into one of concern, curiosity and increasingly, tentative acceptance. Examples of changing attitudes include the last two congresses of the International Federation of Translators (2014 - Man vs. Machine? The Future of Translators, Interpreters and Terminologists, 2017 - Disruption and Diversification); the recent meeting of the AIIC Private Market Sector Committee (PriMS) in Cartagena, Colombia, that revolved around the topic of remote interpreting; and a recent podcast from the Troublesome Terps on remote interpreting. I now see a growing, honest, more even-handed debate of the topic and a possible rapprochement. Standards bodies like ISO/TC37/SC5 and ASTM Committee F43 on Language Services and Products are continuing their deliberations to set standards for different types of remote interpreting. Though all these developments point toward a reluctant warming up to remote interpreting on the part of interpreters, one thing remains abundantly clear -- no remote interpreting service will be successful without qualified interpreters who are able to do their job in a professional, dignified manner. With few exceptions, the field is currently failing in providing the tools interpreters need to justify the effort and investment needed to make the adjustment to remote interpreting. That is why the interpreter leg of the stool is currently the most unstable. Language Service Companies When I originally developed this analogy, the stool had only three legs. I've come to the realization that the stool was missing a vital fourth leg -- language service companies (LSCs). They most often function as intermediaries between end clients and service providers. offering a valuable service to both end user and interpreter. This is a role that is only growing in importance as the frequency and number of interpreted interactions increases, the duration of these interactions becomes shorter, and the number of language combinations multiplies. It is unrealistic to expect individual interpreters to handle the logistics of such complex interactions or to expect large end users to maintain individual contact with interpreters in every language combination they require. Savvy LSCs are developing the workflows and delivery platforms needed to provide the organizational and administrative services and the technological platforms that match the right interpreter with the right end user quickly and efficiently. Because of this, the role of LSCs in the remote interpreting space is likely only to grow. That said, enterprising interpreters have and will continue to develop direct relationships with key end users of their services. This will likely be the case in the remote interpreting space as well, but the cadre of interpreters with direct clients will be small. InterpretAmerica 6: Bringing the Stakeholders Together Remote interpreting is moving forward and being adopted by more and more end users. The pace of this change is astonishing. There are examples of implementations of remote interpreting that have gone terribly wrong and others that are going right and are expanding access to this vital linguistic service. However, the rollout of remote interpreting services in many instances is taking place with few to any guidelines at all, and interpreters are feeling the pressure. This is why InterpretAmerica has issued a call to action to all parties that have a stake in remote interpreting. On October 30, 2017, InterpretAmerica will convene its sixth Summit (You can learn more about InterpretAmerica 6 here). This one-day working meeting will convene (on-site and online), interpreters, professional association leaders, industry leaders, technology developers and end users in pursuit of an ambitious goal: to put into motion a credible process for the creation and implementation of best practices for remote interpreting - across all interpreting specializations and stakeholder groups. Registration opens on September 18, 2017. Given the working format of the Summit, registration will be limited to 50 participants on-site and 80 participants online. However, a livestream of the two Summit plenary sessions will be available to a larger audience. On-site and online participation will be very similar with the exception that online participants won't be able to join on-site participants for lunch in DC. That aside, all participants will be engaged in the same tasks and meetings. By working together, all remote interpreting stakeholders can contribute to making that four-legged stool sturdy, dependable and work well for everyone involved. I hope you'll join us! Do you have a question about a specific technology? Or would you like to learn more about a specific interpreting platform, interpreter console or supporting technology? Send us an email at [email protected]. |
| ADVERTISEMENT |
|
Cadence: at the Cutting Edge of Interpretation
The interpreting market is constantly evolving, with new customers, new technologies, and new modes of delivery. Join Cadence to keep your finger on the pulse of the industry and discover exciting new opportunities to work, learn, and grow.
|
4. Google Translate's Dual System (Premium Edition)
|
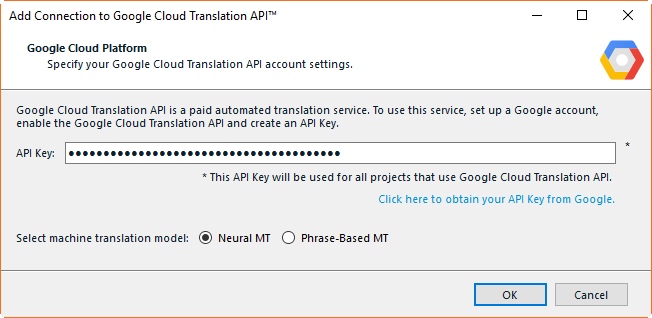
| A blog post by Emma Goldsmith about the GT4T tool mentioned something that sent me on a little bit of a wild-goose chase. (And talking about wild geese, and Canada Geese, in particular: I live at the Oregon coast, very close to the path of the total eclipse a couple of weeks ago. For the great event we went to a large pasture along the majestic Umpqua River where a herd of about 100 wild elk graze. About 60 or so were there on that day, and it was beautiful to see how they responded to the increasing twilight and dropping temperatures -- they were clearly confused, first laid down, then got up again, and eventually hid in the forest. Everyone and everything else was similarly impressed. Even the birds and insects quieted down. Except, you guessed it, for the silly Canada Geese who apparently had not gotten the memo and squawked through the whole event -- very eerie.) Where was I? Oh, yes, the wild-goose chase. Emma mentioned that GT4T, a tool that selectively offers access to a number of machine translation engines, offers access to two different kinds of Google Translate data -- from the neural machine translation engine and from the statistical (phrase-based) machine translation engine. In the 275th edition of the Tool Box Journal, I wrote about Microsoft offering access to both MT systems but mentioned that Google does not. Well, it turns out I was wrong: It does, even though it's not really easy to implement unless your tool gives you ready-made access to it. The default for most languages with Google Translate at this point is neural machine translation. This is what you get if you enter your API code into your translation environment tool (or, of course, what you would receive without a code at translate.google.com). It is, however, possible to "force" Google Translate to offer the statistical machine translation suggestion by setting up the "model" query parameter to "base" (for more information on this see here). This is not done at the point where you set up the use of the Google Translate API in the Google Cloud Platform, but every time you send a request to Google, therefore the infrastructure of your tool needs to provide support for it. The only tool that seems to be doing this painlessly is Trados Studio 2017:
One other tool that is offering access as well is OmegaT, although I would not call it painless (see here), and I admittedly was not able to make it work. Anyway, high time for other tool vendors to get their act together. And why exactly is this relevant? The answer to this lies in how (and, of course, whether) you use MT as a resource. I have long maintained that the most effective way of using MT for the majority of applicable projects is to use it as a repository for fragments rather than suggestions for whole segments that can and need to be edited. Especially in the statistical phrase-based machine translation scenario, the individual fragments or phrases are actually made up of translations that you and I have delivered over the years. They might be wrongly chosen by the machine translation program for the purpose of the current translation, but if they fit, they fit -- and potentially save you from a lot of typing. Neural machine translation suggestions overall tend to read a lot better than phrase-based suggestions, but the way they were generated is different. They did not necessarily use actual phrases that were professionally translated, they just learned from those and generated their own fragments according to those patterns. Fragments coming from these might fit as well, but my sense is that it's less likely to be successful and more error-prone. I'm saying "my sense" because I don't have any data to prove it, so if you have experience I would love for you to share that with me. Either way, I would like to have a choice between the two different MT flavors (or, ideally, access them simultaneously!). And Google, of course, plays an important role because unlike Microsoft or any other of the generic MT vendors, it commits itself to not using your data if you use the API. (And if you want to see a grossly negligent example of this kind of use, see this article.) |
| ADVERTISEMENT |
|
Do you want to learn how to use
Wordfast Pro 5
?
Are you already using WFP5 but want to learn more advanced features? Join Wordfast during its fall Roadshow across North America to learn and network with colleagues. Check out cities and dates here and sign up today. Space is limited and some dates are reaching capacity! |
5. Cloud Quality
|
| I really have not written much about Smartling in this publication. There were a number of reasons for that, chiefly that it's a product primarily marketed to translation buyers. While there are many language service providers and individual translators who work with and on it, that decision is made if they work for a client who uses Smartling. I've been following Smartling very closely, though, and have had many conversations with its CEO Jack Welde over the years. Smartling's recent announcement about the "Quality Confidence Score" seemed very relevant for all of us (Common Sense Advisory's blog post gives a good overview). And here is why: On and off I've mentioned Memsource's reports on translation practices derived from across its cloud-based network (here is a recent example). Rather than looking at individual clients using the tool, they look at anonymized data from all clients and are able to draw conclusions from that data how the average translators interact with the environment and the features provided by Memsource. Smartling used that kind of network-wide approach in its cloud (in which about 7 billion words have been translated so far) to build up a set of parameters that all contribute to an assessment of the quality of any and every translation project. Sound crazy? Not really, if you think about it. While Smartling is not releasing any final list of those parameters, they have shared that some include the expected ability to produce quality work by translator and editor (based on past projects done in the Smartling cloud), duration of edits, comparison of length of strings, handling of codes, typos, and machine-detectable grammar issues, and so on and so forth. The resulting quality score for each project signals to either the language service provider or the translation buyer what to do with the translation. (Assuming the score can be trusted,) a high score might mean that the translated data can be immediately published or that the edits really were unnecessary; a low score might suggest that another proofreading step has to be introduced or linguists have to be switched, or . . .. The client never becomes identifiable in the data being looked at, although the translator, editor, and any other linguist working on the material does, at least internally. While this data is not being made explicit or public, it forms part of the score being given to any translation. Jack called this process "something between a statistical regression model and computer learning," and while it gives me pause and makes me wonder whether this is desirable from the viewpoint of the individual linguist (who of course always has the option not to work within that network), I don't think it's a problem per se and just continues something that has long been in the making. In fact, I recently was interviewed by a journalist about how computer learning and artificial intelligence affect translation. She was thinking of machine translation -- which I happily talked about with her -- but only after I told her that there are many other areas within the translation process and workflow that have also been affected by advanced computer processes. Starting from dynamic spell-, grammar- and style-checking to job assignments to deeper data-driven insights about how translators actually work. Lots of stuff to think about, huh? I'm glad I was able to provide you with something to do this weekend! |
| ADVERTISEMENT |
| memoQ 8.2 coming soon! Want to know how it will make you more productive? Join one of our webinars and find out. memoQ - helping you take delight in your work! |
6. New Password for the Tool Box Archive
|
|
As a subscriber to the Premium version of this journal you have access to an archive of Premium journals going back to 2007.
You can access the archive
right here. This month the user name is toolbox and the password is elkmeadows.
New user names and passwords will be announced in future journals.
|
| The Last Word on the Tool Box Journal |
If you would like to promote this journal by placing a link on your website, I will in turn mention your website in a future edition of the Tool Box Journal. Just paste the code you find
here
into the HTML code of your webpage, and the little icon that is displayed on that page with a link to my website will be displayed.
If you are subscribed to this
journal
with more than one email address, it would be great if you could unsubscribe redundant addresses through the links Constant Contact offers below.
Should you be interested in reprinting one of the articles in this
journal for promotional purposes, please contact me for information about pricing.
© 2017 International Writers' Group
|
|