| ADVERTISEMENT |
|
Not yet tried memoQ 8.2?
WordPress filter. Self-learning MT. Workflow automation. And many more.
Stay tuned! memoQ 8.3 will be released shortly!
|
|
1. Psst! I'm Not Who You Think I Am -- Masking Data (Premium Edition)
|
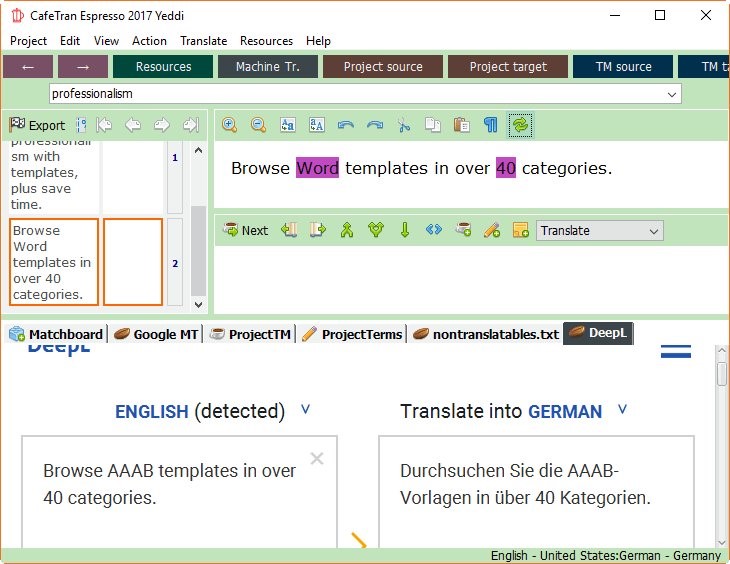
| I was speaking remotely at a conference in Argentina last weekend when one of the participants asked in the Q&A session what machine translation technology providers have to do to make their technology more usable to translators. I can think of a number of things they could do, but another group that can do just as much is translation environment tools developers. So that's what I answered instead. (One of the benefits of speaking remotely is that no one can beat you up afterward, so I figured it was OK not to answer the question too pedantically...) The point is this: There is a lot of data from many different sources that we can access with our translation environments. Yes, there are many issues that still need to be "solved," not the least of which is privacy (let alone accuracy of the suggestions that come from machine translation). But there are many ways that even those concerns can be "remedied" or at least helped by the way we access the data. I have often written about the advantage of extracting data from MT suggestions on the subsegment level, but the examples below show that there are other ways to deal with data creatively -- and I'm sure there are many other ways even beyond those. That's exactly what I mean when I say that translation environment providers bear a great part of the burden to come up with better ways to get to better data. So this week I looked into different ways that translation environment tools -- and especially plugins to such tools -- provide for masking data before sending it to machine translation engines. And I'm glad to report that there are some interesting developments. First I looked at CafeTran Espresso (thanks to Michael Beijer). Among its users, CafeTran has in many ways garnered the reputation of pre-Déjà-Vu-X Déjà Vu as the tool where you can ask the developer anything (reasonable) and he'll implement it for you virtually immediately. (Case in point: I have been encouraging tool vendors to follow Trados Studio's lead to implement a switch between the neural and statistical machine translation option that Google offers for most language combinations, so I sent CafeTran's Igor a personal note asking him to implement it. It took him all of two hours to do it, and it's now available for all.) As another relatively new feature, CafeTran can mask (IntelliWebSearch calls this "obfuscate") confidential terms before sending them to machine translation (this is helpful for product and company names, for instance). Simply enter the terms or phrases in question under Resources> Non-translatable fragments, or use the context menu to add to the list. The term or phrase goes out as a placeholder to the machine translation engine (see "Word" in the example below), and will automatically be reinserted once the machine translation suggestion is transferred.
It's a good idea, though I'm not completely sure how much the quality of MT suggestions will suffer when having to translate placeholders like "AABB," especially when it comes to neural machine translation. (For more on that, see below.) In the screenshot above you can also see that CafeTran is using the new neural machine translation engine DeepL. It avoids the use of an API (application programming interface) by simply embedding the DeepL webpage into its screen estate (via Resources> Web) and making the transfer of text to and from that website available through easy shortcuts. Other tools have found other ways of making the so far official-API-less DeepL available as well (see below). Of course, the masking of confidential terms is not something that CafeTran came up with. Aside from the above-mentioned IntelliWebSearch, the Trados Studio plugin MT Enhanced Plugin for Trados Studio for instance has been offering this for years -- though not in a particularly user-friendly kind of way. A more user-friendly tool is GT4T or Google Translate for Translators (thanks to Emma Goldsmith's blog post and Mats Linder's personal reminder). Five-and-a-half years ago I wrote this about that tool (see edition 206 of the Tool Box Journal):
"Unlike any other tool vendor that I'm aware of, [
GT4T
's developer] Dallas Cao essentially acts as a wholesaler between Google and the translator. The price that you pay for a monthly, semi-annual, or annual license includes the estimated cost of the machine translations that have to be bought from Google. The business model sounds a little risky to me, but Dallas tells me that so far it works for him.
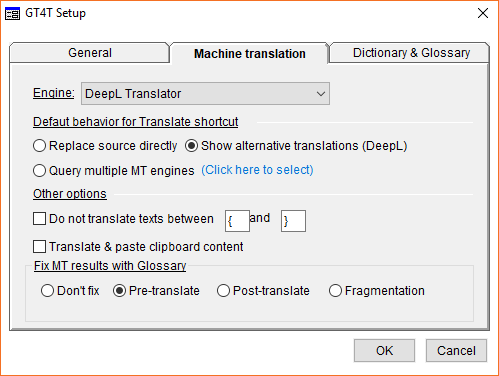
"So, what is GT4T again? Actually quite a bit more than the name suggests. It's a little application that allows you to connect from any Windows application to the Google and/or Bing machine translation engines by highlighting a word, phrase, or text of any length and pressing a shortcut key. Depending on your setting, the text will be replaced with the machine translation, or different translation options will be displayed in a popup window from which you can choose one. If you use a translation environment tool, there are even preconfigured shortcuts to jump to and translate the next segment. "Additionally, it also offers access to a large number of pre-configured and configurable web-based dictionaries, your own Excel-based glossaries and other data sources. After pressing a different shortcut, the found information in those sources is displayed in another little popup window." So what's the difference in the tool now that made Dallas recently write to me: "I resumed my work on GT4T earlier this year. And I feel proud of it now"? Actually quite a bit, and it might very well be worth a second (or first) look for you. Conceptually, GT4T is still a standalone tool that works in any Windows application, and the business model has also not changed. Dallas still acts as the go-between between you and the MT providers (of which there are many more than there used to be), and you just pay a time- or volume-based fee to use GT4T. He uses the APIs (the interfaces that allow one program to communicate with another) of Google, Microsoft, Yandex, and Baidu, but doesn't use and like the "crappy" one for Youdao. I asked him whether he used some of the unofficial APIs that aren't officially sanctioned by DeepL but can be found online. Here's what he said: "They [the online sources] use the same API as I do, but I didn't use their codes. I wrote to DeepL about the API but they say there will be an official one in the future. As a programmer, I am 100% sure the undocumented API is 'leaked' by DeepL people as no one else can. The API is a real full-fledged one designed for programmers." I'd love to hear a response on that from the folks at DeepL (my guess is: we won't). Here is an overview of the setup dialog for machine translation:
You can see a couple of additional interesting things there. For instance, you can query multiple MT engines at a time, or for DeepL (and only for that) you can call up a number of different translation suggestions coming from that one engine. Here's a sample for the first sentence in this paragraph:
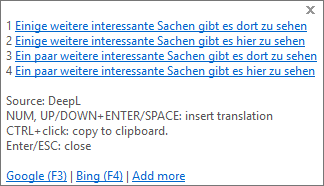
At the very bottom of the GT4T Setup dialog above you can see four options that were just introduced this week. "Don't fix" means that any string can be sent to the machine translation as is; the suggestion that is returned will not be modified by the system. "Pre-translate" means that the source text will be switched with a term that you define in an Excel-based glossary (you can access it on the Dictionary & Glossary tab) before it's sent to the MT engine (in this case I matched "things" with "Sachen," a homonym to "Dinge"). What's interesting about this is that the results, while correct, do not read as fluently as the first option (take my word for it if you don't read German):
I get the same results with "Post-translate" (the only engine where that setting produced different -- and poorer -- results than with the "pre-translate" setting was the statistical Google MT engine). With the post-translate option, the term in the glossary is sent as a placeholder to the MT and then replaced with the term from the glossary once it comes back from the MT. As far as confidentiality goes, therefore, both pre- and post-processing is "safe" (if you do a good job of hiding the relevant terms), but there is the potential of losing some fluency. Of source, the example I chose here is somewhat artificial since I had the program replace a non-proper-name in its plural form. And that also points to a limitation in the whole system. Any replacement is done only with a "perfect match" for the term in question, i.e., you'll have to enter each morphological possibility individually (and things like apostrophes completely throw the system off at this point). As far as the last option ("Fragmentation"), I have a hard time imagining that this will ever come back with good results since this breaks the segment at the place of the glossary term, sends two (or more) separate strings to the MT engine, and then glues them together. As you would expect, stylistically (and otherwise) the result is awkward, especially in language combinations with varying syntaxes.
Overall, I really like
GT4T and it didn't seem to tax my computer too much when it ran alongside other processes. I wish it would introduce a way to access only fragments of each MT suggestion rather than necessarily the whole string.
Sort of similar to GT4T is another tool, or rather a set of tools, from a company called RyCAT. RyCAT is also from China, and it offers something like a dozen (!) different plugins for Trados Studio as well as one for MS Office (the latter is a little reminiscent of Wordfast Classic). I had a very difficult time communicating with the developer John, who also was rather unhelpful in making the Trados MT plugin work for me, so I will not go into great detail here. It is supposed to do a similar replacement of terms as described above for GT4T, but limited to the Trados Studio environment and after some manipulation and limitation of Trados Studio's native capabilities. Feel free to peruse their website or read up on it in Mats Linder's Trados Studio Manual, where Mats apparently had more luck with it than I. |
| ADVERTISEMENT |
|
Focus on Translation not Administration.
Earn more without extra work with AIT bestsellers!
Valid until November 30, 2017.
With Best Greetings,
Your Team at Advanced International Translations
|
|
2. Prospector
|
| Self-confidence is a great and (most of the time) admirable quality, and Serge Gladkoff, founder and president of Russian LSP and translation technology developer Logrus, has that quality in spades when he talks about the tools his company develops. And for at least one of his tools, I can see that he is enthusiastic for a good reason. If you haven't heard it here, you'll have heard it elsewhere: freelance translators typically underperform when it comes to terminological work. We generally don't spend much time preparing projects by setting out terminology and researching it. And even LSPs or translation buyers, who might benefit from such an exercise even more when preparing projects with multiple translators per language combination, more often than not don't do it. Whether for the individual translator or the project manager in an organization, this usually fails to happen because of time pressure and an inability to factor it into a positive ROI (return on investment), even though -- as we all know -- for some projects the ROI is quite clear and the ROQ (OK, I made that up, but let's say it's "return on quality") even more so. (I just stumbled of a discussion that I had with Barbara Karsch, a well-known terminologist, a few years ago and which we published in the ATA Chronicle. At least I found it helpful.) There are a number of tools that allow you to extract terminology from a document or set of documents and then decide which of the terms are usable and which are not. Some translation environment tools offer terminology extraction, like the relatively noisy extraction of memoQ, CafeTran, or Déjà Vu. These processes primarily look at frequency of use of each term (which admittedly is a valid approach but not as the only criterion). Other tool vendors have their separate terminology extraction tools, such as SDL MultiTerm Extract or Terminotix's Synchroterm. While these tools perform better, they're really not widely used (if you don't believe me, try inviting a representative of those companies for a couple of beers at the next conference and then ask whether these tools sell well -- they'll likely have a good chuckle). Then there is the former EU project TaaS, now commercialized and renamed to Tilde Terminology, which not only extracts and normalizes terms from translatable documents but also automatically queries a number of resources for translation suggestions (see edition 229 of the Tool Box Journal for a review of the first incarnation of TaaS). And then there are high-powered, non-translation-specific tools like Sketch Engine, the tool I recently covered in this newsletter (see editions 276 and 277). Logrus apparently felt there was a lot of room in this market (and I sort of agree, actually) and came up with Prospector. Here is how they describe it themselves in their press release: "Prospector uses a combination of proprietary linguistic algorithms and semantic relevancy measures to effectively identify terms, and advanced stemming technology to convert plurals and inflections to the base form. The properly adjusted, semantically relevant terms are arranged, in descending order of importance, on separate sheets of an Excel file: new terms, acronyms, and proper nouns. "One distinguishing feature is that Prospector uses the Corpus of Contemporary American English (COCA) as a 'reference corpus,' which improves term ranking. Maintained by Brigham Young University, COCA is the world's largest [freely available] corpus of the English language." In other words, you can upload a document into the web-based system and it will give you a very impressive list of terms free of noise words ("the," "a," "and," etc.), a list that includes not mere words but true terms, often with modifiers. For instance, I uploaded a short essay and got extractions like "Oregon coast," "Sistine Chapel," "above-mentioned beauty," "abstract art," "cloud formation," "experimental literature," "Martha Graham Dance Company," and "semi-rotten crab leg" (don't ask!). I also got a few non-starters like "effort end" or "individuals might" (ratio of good to bad was about 4:1), and the tool wasn't particularly successful at separating all the proper terms out. But it was very, very good, very similar in quality, in fact, to the extraction tool XTS that Xerox developed many years ago and then sold to a company that is not making it available to regular peons like us anymore. So, if you're a translator who comes from English as your source language and you feel that you need to prepare your terminology better, this is a great tool for you. The same is true if you are a project manager preparing projects coming from English. Of course, the problem with tools like this is that they're completely language-specific and -- in this case -- work only for English (and it didn't sound like Serge had plans to include other languages). The tool is free at the moment. At some point there will be some kind of pricing, but as long as that is reasonable I (and I assume some of you) might be willing to invest into that. I also asked Serge about the fact that the data is processed in Russia, and he seemed surprised at that being a potential problem (which in turn surprised me). While he assured me that the data is not being stored or kept on any Logrus servers after processing, he said he would consider moving it to the cloud in Europe or the US if clients ask for it. (If Prospector is to be successful, this will almost invariably have to happen, methinks.) Oh, and the other tool Logrus has released, Goldpan TMX/TBX Editor, is also a nice (and free!) tool, even though it's not really breaking much ground. This desktop tool allows you -- as the name implies -- to load TMX or TBX (translation memory or termbase exchange) files and edit those as well as do a large number of semi-automated quality checks. The tool is very easy to use, and that is where I would see its greatest appeal. For more advanced users, tools like Xbench or the Okapi tools (including Olifant) are more versatile and powerful. |
| ADVERTISEMENT |
| Need to train your translators and know all about their quality? Show corrections and mistakes to translators, put quality scores, let them discuss... Get reports on translators. And automate it all to save your time. Try TQAuditor! |
3. The Tech-Savvy Interpreter: Lessons Learned from a Pilot Course on Remote Interpreting Platforms (Column by Barry Slaughter Olsen)
|
| The Next Generation of Interpreters and Next-Gen Technologies In early 2017, I pitched an unorthodox idea to my dean at the Middlebury Institute of International Studies -- let me design and teach a course on emerging technologies affecting the interpreting profession. There are enough remote interpreting platforms out there that we could evaluate to keep us busy for an entire semester, not to mention the opportunity to teach students some of the basics about how these new platforms work and the underlying technologies that make them possible. My dean agreed, and I was off and running. After the initial excitement, however, I scaled back the course to last just eight weeks, instead of 15, deciding it was better to start small and grow the course in future iterations. This proved a wise decision. The course filled quickly, and many students joined the waiting list in the hope of being admitted, proving that interest in the subject is definitely there among the next generation of interpreters. They know that they will be using these technologies and want to be informed about them. Surprisingly, they are not as tech-savvy as the millennial generation stereotypes would have us believe but they learn very fast. The only prerequisites were that students had successfully completed their first year of training in consecutive and simultaneous interpreting and have their own laptop computer and a USB headset. My overarching goal for the course was to expose students to these new technologies that are changing where and how we work and give them enough information about them, so each student could develop his or her own informed position. Since the course was not language specific, I had students with many different languages (English, German, Japanese, Mandarin, Russian, and Spanish). This made it easy to test the relay interpreting functions on many of the platforms. The course was not an interpreting course, per se, but rather a technology course. So, I didn't (and really couldn't with most languages) assess the students interpreting performance. The technologies were being put to the test, not the students. Onsite and Online I taught two of the eight classes on site at the Middlebury Institute, the other six were all taught online using the different videoconferencing and remote interpreting platforms that we wanted to test out. As a bonus, the founder of each of the platforms we tested joined us live after our tests to discuss the development of their platforms and their business models. Students then had the opportunity to ask questions. Learning and evaluating a new remote interpreting platform each week requires careful preparation and flexibility on the part of both the professor and the students. Even so, I was amazed at how quickly students would get registered on the various platforms and connect with little or no problem. They were also quick to ferret out any glitches or design flaws that a platform had. One platform representative sheepishly told me, after meeting with my class, that the students had indeed discovered a software glitch and that they were working to fix it as soon as possible. What's Next? I've collected a lot of data from the first iteration of this course and am crunching the numbers now to see what can be learned from the experience. Student interpreters are largely uninhibited by any preconceived notions of how and where simultaneous interpreting can be done, so their insights are largely free of the biases that we "old timers" have developed over the years. That said, many of my students were quick to point out the limitations of remote interpreting and their worries that its adoption may negatively affect working conditions and the nature of the interpreting profession. Concerns that I share. Finally, to finish the course, each student was tasked with writing a personal position paper on remote interpreting. This helped them process everything they had experienced during our tests and formulate a clear position on this controversial topic that will help guide their decisions as they begin their interpreting careers. So, what's next? I plan to teach the course again next year. I'm even contemplating offering the course online to working interpreters who want to learn more about these new technologies and their impact on our profession. My question to you is: "Would you be interested?" If so, send me a quick email at [email protected]. |
| ADVERTISEMENT |
| DS-Interpretation, Inc. Specializing in Conference Interpreting since 1972. New cloud and app-based technologies including Linguali, cutting-edge equipment & sound booths and professional interpreters world-wide. We believe in relationship-based customer service that focuses on meeting the needs of interpreters. As Company Founder, Bill Wood, said years ago: "Interpreters will not be replaced by technology, they will be replaced by interpreters who use technology." Find out why interpreters love working with us. www.ds-interpretation.com |
4. Portage (Premium Edition)
|
| I was intrigued when I read about the latest version of the Canadian National Research Council's machine translation system Portage using "neural network joint models" (NNJM) for their otherwise statistical machine translation system (see my previous report in edition 238 of the Tool Box Journal -- including what "Portage" stands for). So I asked head developer Eric Joanis to talk to me about it. It turns out that NNJM is based on the research presented in this paper. It takes a broader amount of context into account for evaluating the likely accuracy of fragments when assembling complete segments for statistical MT (SMT) suggestions. It accomplishes this by looking at the three words that precede the fragment in question. You won't be surprised to hear that Eric was very happy about the results. As you know, translation plays a large role in Canada (but then, where does it not?) (oh, yes, in the country of my residence, at least when it comes to the general public's imagination...). Anyway, it does play a large role in bilingual Canada, so the National Research Council could not afford to completely shut itself off to developments in neural machine translation (NMT). And it didn't. In fact, it developed its own NMT system alongside the SMT system with the newish context feature. Here is the result as described by Eric: "We built [a system] on the Canadian Hansards corpus [the EN<>FR 'mother' of all bilingual corpora containing the bilingual Canadian parliamentary proceedings]. The training corpus has roughly 16 million sentence pairs, so this is at a scale where one would expect NMT to do better than SMT. Indeed, the experience of our researchers is that for NMT to compete with SMT in terms of BLEU [a widely used algorithm for evaluating machine-translated data] for French-English, you need around 10 million sentence pairs. (For other language pairs that are harder for SMT, that number might be around 1 or 2 million, but for Fr-En it's high.) Nonetheless, we found that with this corpus, SMT outperforms NMT." This is interesting. While the evaluation algorithm BLEU is not uncontroversial, especially when it comes to evaluating NMT, and while one NMT system does not necessarily match another (see the differences between Google Translate, Microsoft Translator, and DeepL even on the level of a generic NMT system), it's refreshing to see that in all the excitement about neural machine translation, well-trained SMT outperforms (also well-trained) NMT for some language combinations (by around 5 BLEU points if that means something to you). One of the advantages of neural in comparison to statistical machine translation is that context can be taken into account more deeply, and this "translates" particularly well for language combinations with widely differing syntaxes, meaning that English into German or Japanese might have seen larger quality gains than English into Spanish or -- in this case -- French. When we speak of machine translation, we often talk about it as if we were not actually discussing languages -- which is a mistake because different language combinations do different things when exposed to machine translation. If you consider this and then add some historical perspective to the relatively short time that MT has been on our radar, things become interesting. When statistical machine translation first came onto the scene in the early 2000s, the excitement among MT developers was so intense that essentially overnight there was no longer any consideration of or regard for the previous rules-based machine translation (RbMT) efforts of the previous 50 years. The gains in SMT at first seemed too significant to ever look back again. To the outside observer this seemed extreme and short-sighted (I presented a paper at the 2006 meeting of AMTA in Boston that called for talks between MT developers and other translation technology users and developers as well as between RbMT and SMT developers -- to say my message was well-received at the time would be overstating it...). In fact, it took until 2010 before machine translation developers felt it made sense to look at "hybrid" systems where both RbMT and SMT might produce better results than SMT all by itself, and this combo then became all the rage. You don't have to be a psychic to predict that this is going to happen again in some form or shape with this new wave of technology in combination with the older approaches. Aside from that, though, we will also see that NMT is not necessarily the best machine translation solution for every language combination (see above) and/or not for every use case. Back to Portage, though. It was interesting to hear Eric talk about their clients' needs (the clients who purchase Portage are typically translation buyers or LSPs who train it either exclusively with their own data or add their own data to the base engine that Portage offers). If trained only with their own data (i.e., not based on a baseline engine that guarantees correct terminology), the amount of data needed for NMT to be useful was so large that, according to Eric, it was essentially impossible to train a neural system when an SMT system could potentially already perform with a few hundred thousand translation units. Unknown terminology has indeed been identified as one of the weaknesses of NMT because the systems tend to either make up terms or simply drop whole phrases altogether. Not surprisingly, confidentiality is also a big concern for Portage clients, even if and when external cloud-based services promise confidentiality, especially if they are in the US. (I mentioned that Portage is Canadian, right?) The possibility of US government agencies accessing data on US-based servers is, according to Eric, much on the forefront of Canadian customers' minds. |
|
ADVERTISEMENT
|
|
Free resources for translators and localization project managers
Whether you're new to translation and localization technology, or experienced in both, SDL Trados has a huge library of resources to help you develop your careers and businesses.
Resource topics include:
|
5. New Password for the Tool Box Archive
|
|
As a subscriber to the Premium version of this journal you have access to an archive of Premium journals going back to 2007.
You can access the archive
right here. This month the user name is toolbox and the password is DavidAlfaroSiqueiros.
New user names and passwords will be announced in future journals.
|
| ADVERTISEMENT |
|
The fastest, friendliest, most affordable TM tool on planet Earth.
Try it out today:
|
| The Last Word on the Tool Box Journal |
If you would like to promote this journal by placing a link on your website, I will in turn mention your website in a future edition of the Tool Box Journal. Just paste the code you find
here
into the HTML code of your webpage, and the little icon that is displayed on that page with a link to my website will be displayed.
If you are subscribed to this
journal
with more than one email address, it would be great if you could unsubscribe redundant addresses through the links Constant Contact offers below.
Should you be interested in reprinting one of the articles in this
journal for promotional purposes, please contact me for information about pricing.
© 2017 International Writers' Group
|
|