A Computer Journal For Translation Professionals |
|
Issue 20-12-319
(the three hundred ninth edition)
|
|
At the beginning of the pandemic I, like everyone else, was worried; but I, again perhaps like many, also was so hopeful that those who survived without loss or injury would ultimately emerge better than before. I hoped that we would learn more empathy, more care for each other, and realize anew that we have so much in common. But though this may have happened for some, I think we can all agree that it's not true for many others. And while I feel so sorry for those who have suffered loss and illness, I also grieve that we (as in "all of us") did not do better at seizing the opportunities this difficult time has presented us with.
I -- and again, I'm likely along many, many others -- have been wracking my brain to imagine what I can do better and what we can do better together to overcome the chasms that have only deepened between our divergent understandings of the world around us -- really, of reality.
Kristen, my wife, and I (Now that's an interesting use of the Oxford comma! Or is it?) live in a very small town in rural Oregon, and we are absolutely and overwhelmingly surrounded by people who perceive reality in relation to the pandemic, politics, and society in general, completely differently from us. W-I-D-E-L-Y differently. But here is the shocker: Most of them are really kind to us. Our neighbors are kind, the clerks in the stores are kind, the restaurant owners are kind when we periodically pick up food, and the hunters and fishermen who share their bounty with us are kind. There's not a shred of fakeness about it; it is truly caring. (And we try to do the same.)
I think this ongoing experience holds two universal keys to answers to the question of what we need to do: First, we need to focus on what we share, and second, we must realize that everyone has numerous identities aside from the ones that are shaped by our worldviews. We are also parents, sons and daughters. We have the same basic needs and desires, are affected by the same weather, fall in (and out) of love, work on our relationships, hurt when we fall, have bad breath in the mornings (unless -- so I hear -- you're a vegan), and feel tired when we get sick or work too much. These and so many other impulses form our various and complex identities and places of belonging, and we share much, much more of these than we don't.
In many of our societies, it seems difficult to bridge what separates us. And when we lack bridges, our view of others' more complex selves is obstructed. So let's focus on our shared identities.
I know that this edition of the Tool Box Journal is outrageously late -- I'm sorry about that. The reason is that the very stimulating conversation with Nico Herbig and Samuel Läubli contained here took a bit longer than expected, plus Kristen (who is my non-Oxford-comma wife after all) and I enjoyed a couple of nice Thanksgiving days last week at our lake cabin.
|
|
Contents
Matching Identities
(More) Advanced Human-Computer Interaction for Translators, a Conversation with Samuel Läubli and Nico Herbig
Looking sharp on video calls with the Webaround green screen (and bonus audio tips) (Column by Josh Goldsmith and Alex Drechsel)
This 'n' That
New Password for the Tool Box Archive
The Last Word on the Tool Box Journal
|
|
New to SDL Trados Studio 2021? Then this is for you!
Get started with our FREE beginner's guide. Become confident with your CAT tool!
|
|
(More) Advanced Human-Computer Interaction for Translators, a Conversation with Samuel Läubli and Nico Herbig |
|
Still on a high from the conversation that I had a couple of months ago with Lynne Bowker, Vassilina Nikoulina, and Sharon O'Brien about Women and Machine Translation (you can now find a version of it in the ATA Chronicle), I had another idea after I read about Nico Herbig's work on a much more hands-on interface for post-editing (for links see below) and Samuel Läubli's ideas about more meaningful integrations of MT in the translation process. I reached out to them, and (spoiler alert!), it turned out to be another really great conversation.
JOST: Samuel Läubli and Nico Herbig, thanks so much for agreeing to have this conversation! The reason why I have invited the two of you is because both of you have worked on usability aspects of translation environments. But before we start, would you like to quickly introduce yourselves?
SAMUEL: Sure! I got really interested in MT when I studied computational linguistics in Zurich, so I went to Edinburgh for my Master's because I heard they had a fantastic research group up there. I graduated in 2014 and got a job offer from an American software company to train domain-specific MT systems. The goal was to increase translator productivity: the company was continually localising more than 180 software products from English into 30+ languages at the time. Initially, I was naive enough to think that I would be able to interact with the translators who used our pre-translations in order to get suggestions for improving the MT systems, but the company used multiple vendors who, often through additional sub-vendors, chopped up and distributed translation jobs to freelancers around the globe. I soon realized that MT quality wasn't the most pressing issue, even with the rather disfluent output that phrase-based systems produced at the time--they could delete that, at least, compared to "exact matches" that were locked (i.e., uneditable) in the CAT tool. I also saw how translators were tasked with translating strings from software user interfaces without any means of seeing what that interface looked like. MT wasn't (and isn't) necessarily good at translating "MENU," but neither were professional translators if they didn't know whether it was part of a navigation component or a description of an item in a virtual restaurant. After two years, I was left with the impression that the way in which the translation industry builds and uses technology was just… broken, really, and moved back into research -- perhaps a bit naive again -- with the hope I could help understand, and then make, things a bit better.
NICO: I studied computer science and am now working at the German Research Center for Artificial Intelligence (DFKI) in Saarbrücken. The project I am spending most of my time on is funded by the DFG (German Research Foundation) and called "MMPE: Multi-modal Post-Editing of Machine Translation." In the project, which is also the primary focus of my Ph.D., we investigate a broad range of explicit input modalities like handwriting or speech input to simplify the PE process. However, we also look at multi-modal implicit input like measuring pupil diameter or skin conductance to estimate cognitive load during post-editing. As this topic is at the intersection of Human-Computer Interaction (HCI) and Language Technologies, we work in tight collaboration between the research groups of Antonio Krüger (HCI) and Josef van Genabith (Multilinguality and Language Technology). To retrieve input from domain experts, we ran our studies with professional translators in a user-centric approach.
JOST: Great. Sounds like talking to the two of you is an even better match than I had first thought! Maybe I can drill a little deeper with each of you about your projects first before we start talking amongst the three of us. Samuel, let's start with you. In the Routledge Handbook of Translation and Technology, you co-authored a chapter with Lilt co-founder, Spence Green, where you looked at the afore-mentioned HCI and evaluated a number of different ways to interact with machine translation suggestions. One of the results was to highlight the need for adaptive machine translation systems and the other seemed that translators had a difficult time to adopt a new working environment. Correct me if I'm wrong on that.
Just a couple of weeks ago you gave a talk in which, according to its description, you covered the following: "Having faced tremendous resistance throughout the late 1990s and early 2000s, translation memories (TMs) are now considered indispensable productivity tools for professional translators. TMs are great at providing (partial) translation suggestions in the form of fuzzy or exact matches, but CAT tools are currently not too creative in utilizing these matches: they just display them to the user. In this talk, we take a look at how machine translation (MT) technology can ingest fuzzy matches to generate better and more domain-specific translation suggestions, or transform exact matches to comply with context-dependent linguistic requirements in the target language. We also discuss who's to blame about the fact that these features are not yet available to professional translators."
Naturally, we all would be interested in finding out who's to blame, but also whether you see wide-spread changes in a number of translation environments on the immediate or mid-term horizon. If so, what kind of changes, and will they be easily embraced by translators?
SAMUEL: TMs produce so many inadequate suggestions if you think about it. Even exact matches often aren't too exact. Think about linguistic properties that are implicit (or undefined) in the source but explicit in the target language, such as politeness when translating from English to German. "You" will be translated as either "Sie" (formal) or "du" (informal), but an exact match for "You can win fantastic prizes" that comes with "Gewinnen Sie fantastische Preise" on the target side really isn't that great in an informal context. Since politeness can be controlled in and partial translations can be incorporated into NMT, these "exact matches" could be adjusted automatically. However, the NMT system will need an indication of the desired politeness and the target side of the match to transform to do so. Since most CAT tools don't integrate but merely connect to MT systems, they only send very basic information, typically the source segment to be MT-ed alongside two language codes. If CAT tools were that loosely coupled with TMs and TBs, you'd never see features like real-time subsegment matching or predictive typing. So if you're asking yourself why MT doesn't update as you edit a target segment or doesn't respect the very terms displayed in the CAT tool's terminology pane, it's not because MT can't do that, but because the CAT tool doesn't send it to MT.
JOST: Let me interrupt you briefly (we're still interested about who's to blame!). I think that sounds a little too pessimistic of a view on both translation memories and the current use of adaptive machine translation. On the latter, I agree with you that much more needs to be done, but between SDL's adaptive MT, Lilt's MT and ModernMT's implementation in a number of CAT tools, there is some progress, right? And your examples on weaknesses of TM matches make sense on a theoretical level, but I'm not sure how much of that is practically applicable when using project-specific TMs.
SAMUEL: I absolutely agree with you; there certainly is progress. However, the idea of adaptive MT is currently centered on post-editing. If the engine suggests a wrong term, for example, it will (hopefully) learn to avoid that mistake once the user has corrected it. But why does the system need to make a mistake in the first place? If the user works with a TB, the MT engine could (and can, technically) use correct terms right away; if the user works with a project-specific TM, the MT engine could (and again, can, technically) learn from the exact and even fuzzy matches in that TM before it provides a suggestion for the first segment. MT systems shouldn't only adapt once the user corrects mistakes -- they should adapt to project-specific resources upfront.
So if you're asking who's to blame that modern MT features aren't available to translators yet, it's clearly the CAT tool manufacturers. I don't really see changes in widespread CAT tools on the horizon, which really puzzles me. Then again, this may be a chicken-and-egg problem: are these features not available because translators are not asking for them, or are they not asking for them because they've never seen them implemented in a tool? Personally, I could well imagine that translators would embrace changes like neural fuzzy repair and NMT output toggles for things like politeness or other linguistic aspects as long as they are easy to use and well visualised. (But with fundamental design choices dating back to the 1990s, widely used CAT tools aren't exactly a prime example of effective, user-centred data visualization. . .).
JOST: That sounds like a perfect segue into what Nico is doing with his concept of MMPE or a "Multi-Modal Interface for Post-Editing Machine Translation." I got really excited about your post in Kirti Vashee's blog and the articles and videos that you provided links to at the end of the post. A number of years ago, I wrote an article about a tactile approach to translation, and while I certainly did not have all the tools in mind that you have made available, this was very similar to what I was thinking. Your MMPE includes computer interaction via the keyboard/mouse, touch, voice, and handwriting -- what a great idea. The immediate questions that I have are these: this seems to be quite language-specific since voice and handwriting only work for a select number of languages, correct? And will your prototype make it into existing translation environments? Or, to rephrase the last question, what would have to be done for that to happen?
NICO: Indeed, PE requires very different interactions than traditional translation. We see a change from "production," where all text had to be manually entered, to "supervision," where the task changes to capturing and correcting mistakes, as well as manipulating and recombining useful proposals. Naturally, this change already started with TMs, but the better MT gets, the more we move away from the production paradigm to supervision and collaboration with the machine. We do not question that for production, mouse and keyboard are very good tools, but we believe that for the changed interaction pattern in PE other modalities could be very helpful, not as a substitution for mouse and keyboard, but as a complement. This is what we explore in MMPE, where we, for example, found that a digital pen and finger touch are very well suited for deletion and reordering operations.
Regarding your question on language support: the transcription of handwritten text or speech input nowadays works well with many languages. You just need to exchange the underlying machine learning model with one that was trained on data in the target language. One would, of course, need to define the speech commands in other languages as well, but we tried to keep our code rather flexible by having the commands in separate files outside of the source code. Further studies would be needed to say for sure how well it works with other languages and to explore changed interface layouts for e.g. right-to-left or logographic languages.
What will need to be done to integrate such modalities into existing CAT tools? That is a good question, Jost. It depends a lot on the input modality. Most computers have an integrated microphone, and now with the pandemic, many people probably also own a headset. So for speech input, the CAT developers can basically start integrating dictation and also speech commands. E.g. memoQ is already offering an iOS app which transcribes your speech input and sends it to their CAT tool. Pen and finger touch input could also be integrated rather soon. Many laptops nowadays have touch screens, and tablets are becoming more and more common. In general, I believe that with higher quality MT output, PE on tablets might become doable, especially with good handwriting, touch, and speech support. But I assume the market is currently too small for CAT companies to invest in this. Other modalities we are currently exploring, like eye-based interaction (e.g. you look at a word and say "delete"), or mid-air gestures (point at a word, and do a hand gesture to delete), are interesting from the research perspective but no one has these tracking devices in a standard office, so I believe it will take a long time until we see something like this in commercial CAT tools, if at all.
JOST: That makes sense but what I had in mind was whether it would somehow be possible to use your MMPE or aspects of it and essentially connect it to existing translation environments via API or some other mechanism. I think that otherwise, translators would have to wait an awfully long time for existing tools to implement it. Also, I'm not sure that I completely agree that the interface you are proposing is not necessarily suited for TM-based work.
NICO: Integrating aspects of MMPE into existing CAT tools is probably not that easy, which is why we also chose to start from scratch. As Samuel already said, many CAT tools still follow outdated design patterns, making the CAT tools look more like spreadsheets and not like modern websites and applications. As an example, take handwriting: we heavily rely on the MyScript API here, which is working great and could also be integrated into existing CAT tools. But if you try to hand-write into the small space that most translation environments provide for editing, there is no way that it's going to work well. The same holds true for touch reordering, eye tracking, or mid-air gestures: stronger interface changes are required; if you just try to squeeze it into existing tools, I believe the user experience will suffer so strongly that you will stick to your mouse and keyboard. However, we are currently adding documentation and plan to open-source MMPE soon in the hope that people try it out and give us further feedback. Who knows? Maybe even some CAT developers might decide to build certain aspects into their tools; I'd love to see that.
I do not disagree regarding TM: the newly explored modalities might also help with TM-based work, especially when the match scores are high. We just have not tested that, so I can only guess here. For our study, we also chose to pre-fill the editing box with the MT proposal. If you would do the same with highly matching segments from TMs, it should basically be the same. I just believe that the new interaction possibilities mostly make sense to quickly fix a variety of smaller changes. In TMs, one part of the sentence might be perfectly matched while another part is not matched at all. If you then need to insert 10 words, typing or maybe dictation are great, but handwriting and finger touch might help less in this setting. However, for low-quality MT, you might want to re-translate larger portions of the segment as well, where again typing and dictation are probably better than other modalities. So I'd rather say that the new modalities show their benefits for highly matching segments from TM or high-quality MT because they allow you to very quickly change the few remaining mistakes, like quickly grabbing a few words and moving them somewhere else. Here, you produce less and supervise the machine more.
continued below . . .
|
|
Corporate Language Management powered by STAR CLM
Watch the short video for more information on STAR CLM functionality and usage:
|
|
(More) Advanced Human-Computer Interaction for Translators (continued) |
|
. . . continued from above
JOST: A couple of other things that I like to discuss with both of you are these: Why are we stuck with the concept of post-editing one machine translation suggestion? Why are we not, for instance, looking at how we could harvest several machine translation suggestions simultaneously by using mechanisms like auto-suggest (which would mean that we don't even have to look at the various MT suggestions -- we just see what matches our keystrokes)? And also -- I think that you, Samuel, already alluded to it -- why don't we look at a closer integration of our three most important resources (TM, MT, and TB) with each other and achieve better results that way?
NICO: Indeed, we've been asking ourselves the same thing. Therefore, we are currently adding multiple MT proposals in MMPE, where we penalize similar MT outputs. No one wants to see almost the same proposal 3 times, since a normal PE of a single proposal would be quicker than that. But we believe offering multiple high quality and diverse outputs might help. Especially for shorter sentences, a translation very similar to what you aim for is most likely among the proposals. For long sentences, however, mentally processing multiple proposals might just take longer and be more cognitively demanding than directly post-editing a single proposal. At least this is what I would expect now; we'll know more when we run a study on this.
In parallel, we are also looking at more interactive ways to PE, where you click on parts of the MT proposal that you don't agree with and get alternatives. I believe that this, in combination with touch and handwriting, could really be a nice approach to PE, and could also work well on tablets.
SAMUEL: Nico brings up an important point: showing too many alternatives could lead to cognitive friction. The prototype of Lilt offered both what you refer to as auto-suggest, Jost -- a single suggestion for word, phrase, or sentence completion that adapts to the user's input, rendered as ghost text -- and multiple word or phrase translation alternatives presented in a drop-down menu. The latter were used so rarely that they didn't make it into the final product.
However, regardless of how suggestions will be visualised, it is vital that they combine all of the resources available to translators: TMs, TBs, and MT. I like your idea of using multiple MT engines for auto-suggest, Jost. At TextShuttle, we're using a technique called Diverse Beam Search to produce diverse translation variants with a single engine. The rationale is that even MT engines from different providers typically produce very similar translations for many sentences and because NMT systems always generate multiple translation variants behind the scenes as they generate a target sentence, enforcing variability comes at almost no computational overhead. In a word: it's easy to generate multiple translation variants for a given source sentence with a single NMT system, but as long as CAT tools don't query and visualise them, there's no way for professional translators to take advantage of them.
JOST: Thank you so much for this, Nico and Samuel! It feels like we could continue talking about this for a long time, but it seems even more important at this point that translators start considering some of those things, and that tool makers start a dialogue among themselves and see whether they can implement some of the changes you are mentioning. Or maybe there is even a young team of developers that will read this and will say, "Yeah, there are so many good ideas in this, that I think I can build something new and interesting and become super-rich selling it" (well, the latter is not going to happen but the former might).
My biggest take away from our discussion is that just because we think we have found a widely accepted way of working, does not mean that we couldn't and shouldn't be questioning it on a continuous basis and, well, making it better. All this excites me greatly, partly because it goes to show that professional technical translation (and with "technical" I mean to include virtually everything non-literary) is alive and well, even as research tries to find better ways to facilitate it.
Thanks again, and let's stay in touch.
|
|
Year-End memoQ Sale for Tool Box Journal Subscribers
You don't have your own memoQ translator pro license yet? memoQ offers 30% off on all new translator pro licenses for Tool Box Journal subscribers until December 14, 2020.
|
|
The Tech-Savvy Interpreter 2.0 - Looking sharp on video calls with the Webaround green screen (and bonus audio tips) (Column by Josh Goldsmith and Alex Drechsel) |
|
We don't know about you, but we've been in a heck of a lot of online meetings recently.
And if you're anything like us, your home office doesn't look great on camera. (Josh and his partner work from the same room, while Alex shares the basement with his son's drum kit.)
As a freelancer, it pays to look professional -- whether you're having an online meeting with a client, interpreting from home or collaborating with others on your volunteering activities.
So how do we set up our home office to win over clients?
In this month's column, we'll share tips for looking and sounding great on video calls. We'll also let you in on a little secret: a portable green screen so you can look like a pro in no time.
The right sound
If you're going to take the floor during online meetings, you'll want others to hear you clearly and understand what you have to share. So you'll need a good microphone. The easiest option is often to use a good USB headset, since the microphone that's built into your laptop or webcam usually picks up a lot of room noise, echo and all kinds of other sounds. Even if you turn your head while speaking or look down at your notes, your headset microphone will always be at the right distance from your mouth, so what you say won't be lost!
Rule out wireless headsets or headphones like the ubiquitous AirPods from Apple. They're fine for listening, but their microphones just don't cut it and the Bluetooth connection can cause connectivity issues. Don't forget that wireless devices need power -- if you don't charge them, they might just let you down at the worst moment.
In a pinch, the in-line microphone on smartphone earbuds will do the trick. Then again, these microphones can rub up against buttons or fabric, so they need to be handled with care.
If you prefer to use a more professional USB-microphone along with your favorite headphones, consider picking up an inexpensive boom arm. This will ensure your microphone is at the correct distance from your mouth and doesn't pick up any bumps, clicks or shuffling papers.
The right look
First, lighting. If you have a window, sit facing it. That gives you plenty of good light, for free!
But the weather can be fickle -- especially at this time of year and in our neck of the woods. We recommend picking up an inexpensive ring light. This provides soft, balanced light. Place the ring light directly behind your webcam with a stand, which is often included in the box. Some lights even come with a clamp in the middle for your smartphone.
Second, framing. For most virtual meetings, you'll want to be in the center of the shot. Put your webcam or camera at or above eye level, no higher than your hairline. You should see your shoulders and entire face. Look into the camera from time to time when you're speaking to enable your listeners to make eye contact.
Your camera should be steady and at eye level. A tripod or stack of books can help in a pinch. If you want to use your smartphone as a webcam, there are some pretty cool apps out there, too. (Check out this video for a review of Camo, a handy app that turns your iPhone into a webcam for your Mac or Windows computer.)
Virtual backgrounds and green screens
If you're anything like us, you've seen your fair share of virtual backgrounds. And some of them can be pretty terrible, with blurry edges, pixelated images, distracting video backgrounds, and bits of the background bleeding through.
The secret to a good-looking virtual background is to get yourself a green screen. However, most of us simply don't have a way to hang one in our home office.
Luckily, there's a solution: the Webaround, an inexpensive green screen with a twist.
Unlike most green screens, the Webaround attaches to the back of your chair. When you're not using the screen, simply fold it up into its convenient carrying case, then stow it out of sight. When you need it again, pull it out of its bag and it springs open to its full size. The built-in stabilizer aligns the top of the Webaround flush with your chair. Set-up time: under fifteen seconds.
The Webaround comes in different sizes. The smallest unit -- at 42 inches (107 cm) -- is good for those working in smaller spaces, while the 52-inch (132 cm) model is a great all-around purchase. And the 56-inch (142 cm) Webaround is awesome if you've got the space and a wide camera angle. All three units collapse to just 21 inches and are made of spring steel and polyester.
The Webaround is available in green, gray and blue, but unless you're a lighting or video expert, we'd recommend sticking with green. That's simply because green isn't present in human skin tones, and people rarely wear green clothing, so they're unlikely to blend into the background. The chroma-key features in virtual meeting tools like Zoom are also designed for green screens.
At first, getting the Webaround back into its carrying case can be tricky. To make things easier, we've put together a comprehensive video so you can see the Webaround in action -- and learn to pack it up in just a few seconds.
Another perk: if you're headed off on a trip but want to do some filming or need to be on video calls, just pop it into your suitcase.
You can currently pick up a Webaround for between 60 and 75 bucks. In our view, the affordable price, easy handling and flexibility make it one of the best green screens for those who want a simple solution that works right out of the bag. And it's durable: Josh has been using his almost daily for over six months, and it's still in pristine condition.
The Webaround folks have been kind enough to offer a 10% discount to our readers. Plus, they're raffling off a FREE Webaround to the Tool Box Journal community! You'll find the link to enter the contest below. Please note: Due to the current situation, this contest is limited to US residents.
PS. Questions or ideas about interpreting technology? Drop us a line at [email protected]! We do the research, so you don't have to.
|
|
Contest ends December 15, 2020
You can look great on camera AND take 10% off your portable green screen with this link and coupon code techforword.
|
|
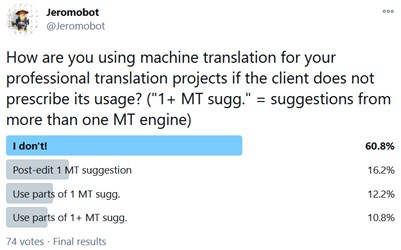
I did a super-unscientific survey on Twitter last week about machine translation usage among professional translators. (I did not specify "technical translators" in the query -- I assumed that literary translators would know not to answer.) |
|
What surprised me most was that only 8 of the 74 who participated used more than one MT engine to elicit suggestions. Clearly everyone has their own working preference, and not every tool allows a user to use multiple MT engines simultaneously, at least directly. But if you are using MT as one of your resources and you don't have a trained engine (which is likely the case here since the scenario presupposes that your client has not asked you to work with MT), I don't completely understand why using multiple MT engines is not a more often-used workflow option. Is it because of a feared information overload? Or because there is no easy way of doing it? Or is it because many have simply not considered it yet?
A few editions ago, I mentioned that TAUS was going to start a data marketplace and at the same time discontinue the terminology search as part of their previous Data Cloud offering. If you read what I wrote, you'll remember that I pleaded with them not to shut that down; I asked them instead to leave it as an unmaintained legacy service that would allow translators to use it as long as it's helpful. I'm sad and frustrated to report that they apparently decided otherwise. I think it's a mistake and something that could easily have been left up as a sign of appreciation that the data they have been collecting and are now trading is in fact data generated by translators -- the same people who also use the terminology search. Oh, and as far as the data marketplace they've now launched? I participated in the TAUS Data Summit a couple of weeks ago, and it was interesting to see how neutral or negative most of the speakers were about the marketplace. So maybe that will not be as successful as hoped for after all.
A few years ago -- back when we could still travel and go to conferences, remember? -- I gave a talk in Rome. I thought to myself it would be a really good idea to start the talk by singing Adriano Celantano's Una Festa Sui Prati. It was the first time I was boo'ed at a talk. I think it was only partly because I sang badly (I did!). Even more, it seemed that they really were not fans of Adriano Celantano, and especially that song (which apparently was a dud in Italy but a big hit in Germany, where I grew up, and where I kept sneaking my parents' Una Festa Sui Prati single to swoon along to).
I'm so glad I have now encountered Celantano's Prisencolinensinainciusol, which was a bigger hit in Italy and elsewhere and is quite remarkable from a linguist's perspective (I promise never to sing it for you!). Its lyrics consist of pseudo-English that sure sounds dynamic -- just like its video that you might already have seen on social media -- but didn't make any specific sense, aside from proving that, at least in 1972, everything that sounded English was likely to be successful. I'm glad we're beyond that.
And then there is this: A newly cultivated Chinese rose ( Rosa chinensis) has been named "Translator" (翻译家) (see here): |
|
Translating PDFs is easier and quicker with TransPDF
- Supports Arabic, Hebrew, Persian and Urdu PDF input and output
- Integrated into Memsource, memoQ, ONTRAM
- Compatible with all CAT tools.
- Fast log-in for Proz members.
Try it FREE for your next PDF project. |
|
New Password for the Tool Box Archive |
|
As a subscriber to the Premium version of this journal you have access to an archive of Premium journals going back to 2007.
You can access the archive right here. This month the user name is toolbox and the password is compassionmeanscaring.
New user names and passwords will be announced in future journals.
|
|
The Last Word on the Tool Box Journal |
|
If you would like to promote this electronic journal by placing a link on your website, I will in turn mention your website in a future edition of the Tool Box Journal. Just paste the code you find here into the HTML code of your webpage, and the little icon that is displayed on that page with a link to my website will be displayed.
If you are subscribed to this journal with more than one email address, it would be great if you could unsubscribe redundant addresses through the links Constant Contact offers below.
If you are interested in reprinting one of the articles in this journal for promotional purposes, please contact me for information about pricing.
© 2020 International Writers' Group
|
|
|
|
|
|
|